
Perla is a conversational agent (chatbot) designed to screen Internet users for symptoms of depression.
This blog post is an informative summary of the article:
Arrabales, R. (2020). Perla: A Conversational Agent for Depression Screening in Digital Ecosystems. Design, Implementation and Validation. arXiv preprint arXiv:2008.12875.
To learn the details of the investigation, see the full article at: https://arxiv.org/abs/2008.12875 (a Spanish version is also available).

The main objective of this project was to check if it is possible to screen for depression on digital platforms without having to resort to classic self-report techniques.
A screening or triage is a process by which the health status of a population is quickly and relatively superficially analyzed. The advantages of screening, in this case for depression, is that it allows early diagnosis. That is to say, detect cases of depression as soon as possible, since the sooner a psychological problem is identified, the sooner we can act and we can have a better prognosis.
The problem is that reaching large numbers of people is difficult, especially in digital ecosystems, where it is increasingly difficult to attract the attention of users and get them to commit to performing a psychological test.
The traditional way of conducting mass screening is by providing users with a self-report questionnaire (that is, a questionnaire they fill out themselves). In the case of depression, the Patient Health Questionnaire (PHQ-9) is often used. If you want to see what these screening tools are like, you can try it here (Spanish version).
One way to reach more people in an automated way is to replace the self-report tool with a chatbot (or virtual assistant, or conversational agent). As we have seen in this research, users generally prefer to chat with an artificial agent rather than fill out a questionnaire.
“
People prefer to chat with an artificial agent rather than fill out a questionnaire, even though the second option is faster.
“
In the research carried out we have verified that when offering users both options, 3 out of 5 users prefer to chat with Perla, instead of simply filling out the questionnaire.
Once we have managed to attract the interest of the users towards the interaction with Perla, our concern is that the results obtained by the artificial agent are as valid and accurate as those that would be obtained with the original questionnaire. Perla’s job in this regard is to conduct a structured interview based on the original questions from the PHQ-9.
In this area, the use of Artificial Intelligence techniques is of great importance. Specifically, Natural Language Processing (NLP) and Natural Language Understanding (NLU). The main idea is that Perla has to be able to understand the answers that the user gives and translate them into a score. The score obtained for each interview question is used to calculate a final score that indicates the risk of suffering from depression.
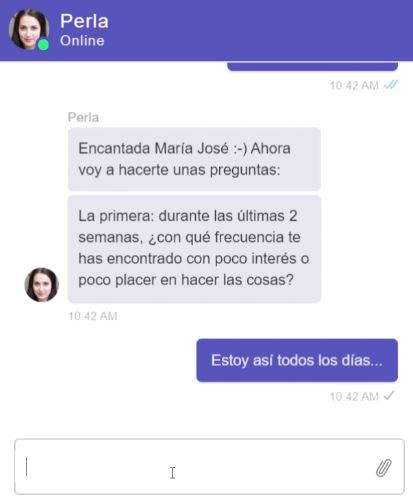
In other words, when talking to Perla, the user does not have to choose between various Likert-type options (for example, “very often”, “once in a while”, “never”, etc.), but can express themselves openly and answer to the question as they would to a human interviewer. The great difficulty here is that Perla must know how to correctly interpret any type of response from the user.
To verify that Perla fulfills its mission correctly, we carried out a validation study in which a group of users performed both the traditional test (self-report) and the interview with Perla. Once we have the data from the two tools, we compare them and calculate the errors that Perla makes with respect to the results of the PHQ-9 test.
“
The validation study shows that Perla has a sensitivity of 96% and a specificity of 90% in detecting symptoms of depression.
“
The 96% sensitivity means that Perla is very good at detecting positive cases of depression. That is, out of every 100 people who really have depression, Perla is able to identify 96 of them (the other 4 would be false negatives).
The 90% specificity means that Perla is also good at detecting negative cases, which do not have depression. That is, out of every 100 people who do not have depression, Perla is able to identify 90 of them (the other 10 would be false positives, for whom Perla “thinks” they have depression, but in reality they do not fully meet the criteria for that diagnosis).
Therefore, we see that Perla, as the one in charge of screening, tends to be conservative and in doubtful cases she is inclined to err by giving a false positive rather than a false negative. As we are talking about a massive screening process and it is not a final diagnosis, these detection properties seem quite adequate to us.
Here you can see how Perla works (in Spanish):
If you are interested in seeing the detailed data analysis from this study, you can check out the Perla project repository on GitHub.
For more information, check out the clinical psychology product page.